
PyTorch Inductor 中 fuse_nodes 融合流程深度解析
作者: Jiakang Huang,Xueyan Zhang
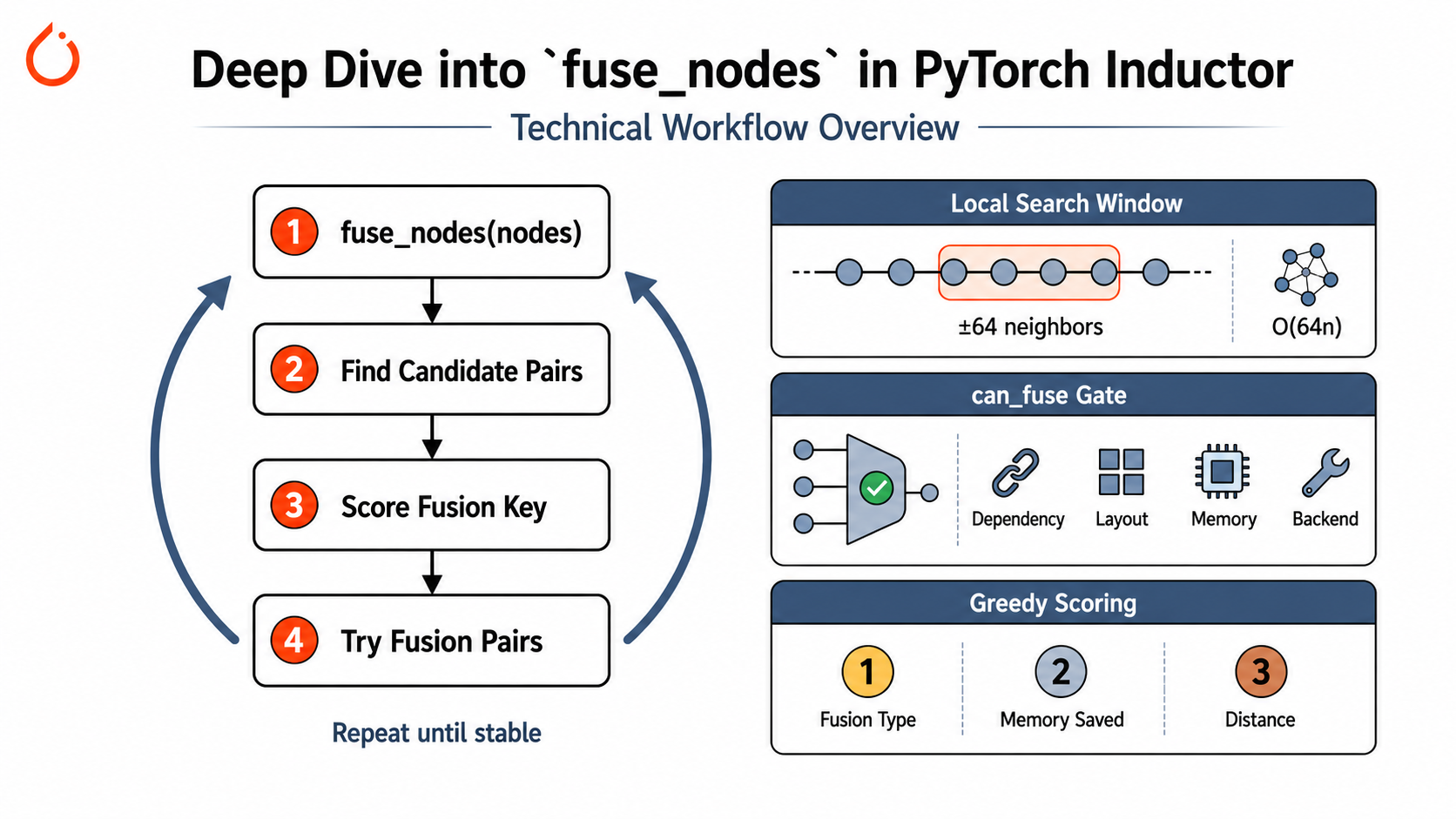
总览
下图展示了 fuse_nodes 的完整调用链。整个过程可以概括为一句话:在节点图上反复寻找可融合的节点对,按优先级打分排序,然后依次尝试真正的融合,直到图不再缩小为止。
fuse_nodes(nodes)
│
└─► fuse_nodes_once() ×最多10轮,节点数不变或=1时提前停止
│
├─ 1. get_possible_fusions() ─────────────────── 枚举所有候选融合对
│ │
│ ├─ [Loop 1] 按 buffer_name 分组
│ │ 对每个 fusable node,按其读写的 buffer 归入 dict
│ │
│ ├─ [Loop 2] 在每个 buffer 组内 check_all_pairs()
│ │ │ ► 窗口优化:只看前后各64个邻居 → O(64n) 而非 O(n²)
│ │ │
│ │ └─► can_fuse(n1, n2) ──────────────────── 8大类门控检查
│ │ │ ① 自身判等 ⑤ 顺序/拓扑依赖
│ │ │ ② 特殊节点拦截 ⑥ 数据类型兼容
│ │ │ ③ Template快速放行 ⑦ 内存/尺寸约束
│ │ │ ④ Grouped节点禁入 ⑧ 其他后端限制
│ │ │
│ │ └─ 若失败 & node2 是 template/foreach
│ │ → 反转方向再试 can_fuse(n2, n1)
│ │ (容器节点可以"吸收"其他节点)
│ │
│ ├─ [Loop 3] aggressive_fusion 模式
│ │ 按 node.group 再分一次组,组内再 check_all_pairs()
│ │
│ └─► get_possible_fusions_with_highest_priority() ── 去重 & 选优
│ │
│ ├─ get_backend(device).get_fusion_pair_priority(n1, n2)
│ │ 后端接口:CPU/CUDA 各自决定融合方式的优先级
│ │
│ └─ 同一 pair 可能来自不同分组路径 → 只保留最高优先级的那条
│
├─ 2. score_fusion_key() ─────────────────────── 对候选对打分排序
│ │
│ └─► V.choices.score_fusion()
│ 基于三个维度:
│ • 融合类型 (template / reduction / ...)
│ • 预估节省的内存带宽
│ • 原始图中的拓扑距离(越近越优先)
│
└─ 3. _try_fusion_pairs() ────────────────────── 按排序顺序逐对尝试融合
排序至关重要:若先融合 (A,B),则 (B,C) 自动作废
阶段一:寻找候选对 - get_possible_fusions
这一步的目标是从整张图中筛出所有“有可能且有价值”被融合的节点对。
Buffer 分组 - 融合的前提
代码首先遍历所有 fusable node,按照节点读写的 buffer_name 建立一个分组字典。背后的直觉很简单:如果两个节点不共享任何 buffer,融合它们大概率没有收益,既不能省掉中间 buffer 的分配,也不能减少内存搬运。因此只在同一个 buffer 组内部做配对检查。
窗口优化 - 控制搜索空间
在每个 buffer 组内调用 check_all_pairs 做两两配对。这里有一个关键优化:PyTorch 默认只在节点列表的前后各 64 个邻居之间检查。对于长度为 n 的节点列表,候选对数量上界是 64 * n,而非朴素的 n^2。这让融合搜索在大型图上依然可控。
can_fuse - 8 大类门控
每一对候选都必须通过 can_fuse(node1, node2) 的严格审查。检查项至少包括:
- 自身判等:
node1 == node2,直接跳过。 - 特殊节点拦截:
FusedMixOrderReductions等已融合节点不允许再次融合。 - Template 快速放行:template 节点有专门的短路判定通道。
- Grouped 节点禁入:
GroupedSchedulerNode已被分组调度,不再参与融合。 - 顺序依赖检查:最重要的一项,确保融合不会打破数据流的拓扑顺序。
- 以及数据类型兼容、内存和尺寸约束、后端限制等更多细粒度校验。
一个有趣的细节:如果 can_fuse(n1, n2) 判定失败,但 n2 是 template 或 foreach 节点,代码会反转方向再试一次 can_fuse(n2, n1)。原因在于 template 和 foreach 本质上是“容器节点”,它们可以把别的节点“吸收”进来,所以方向不同,融合语义也不同。
激进模式
当 config.aggressive_fusion 开启时,代码会额外按 node.group 再做一轮分组。调度器认为同一 group 内的节点属于同一个更大的逻辑单元,值得更积极地尝试融合。
阶段二:去重与打分
去重 - get_possible_fusions_with_highest_priority
同一对 (node1, node2) 可能从不同的分组路径被重复选出,一次来自 buffer 组,一次来自 node group。不同路径意味着不同的融合方式,而我们只需要保留最优的那一种。
去重的核心依据来自后端接口 get_backend(device).get_fusion_pair_priority(node1, node2)。这是一个动态分派调用,先根据 device 找到对应的后端,例如 CPU 或 CUDA,再调用该后端自己的优先级评估逻辑。基类默认返回 0,但各后端可以覆写。
打分 - score_fusion_key
去重后的候选对会经过 V.choices.score_fusion() 打分。打分维度包括:
- 融合类型:template 融合、reduction 融合等不同类型权重不同。
- 预估节省的内存带宽:融合后能少搬多少数据,这是最核心的收益指标。
- 原始图中的拓扑距离:距离越近的节点对越优先融合。
所有候选对按分数从高到低排序,排序结果直接决定融合的先后顺序。
阶段三:尝试融合 - _try_fusion_pairs
这是真正执行融合的地方。排序至关重要:候选对按分数从高到低依次尝试,一旦某个节点已被融合,包含该节点的其他候选对自动作废。
举例来说,假设候选列表中有 (A, B) 和 (B, C),且 (A, B) 分数更高。那么 (A, B) 会先被融合,之后 (B, C) 就不再可行,因为 B 已经消失在融合节点 AB 中了。
这种贪心策略加上前面精心设计的打分函数,使得 Inductor 能在合理的时间内找到一个高质量的融合方案。
小结
fuse_nodes 的设计体现了几个工程上的权衡:
- 窗口优化把搜索复杂度从
O(n^2)压到接近O(n)的实践表现,让大型图也可行。 - 多路分组通过 buffer 组、node group 和 aggressive 模式,在不同粒度上捕捉融合机会。
- 后端分派让 CPU 和 CUDA 可以各自定义融合偏好。
- 贪心排序用一个简单但有效的策略,在候选对之间做出取舍。
整体来看,这是一个“宽搜索到窄筛选到贪心决策”的经典优化流程。