
Deep Dive into fuse_nodes in PyTorch Inductor
Authors: Jiakang Huang, Xueyan Zhang
Overview
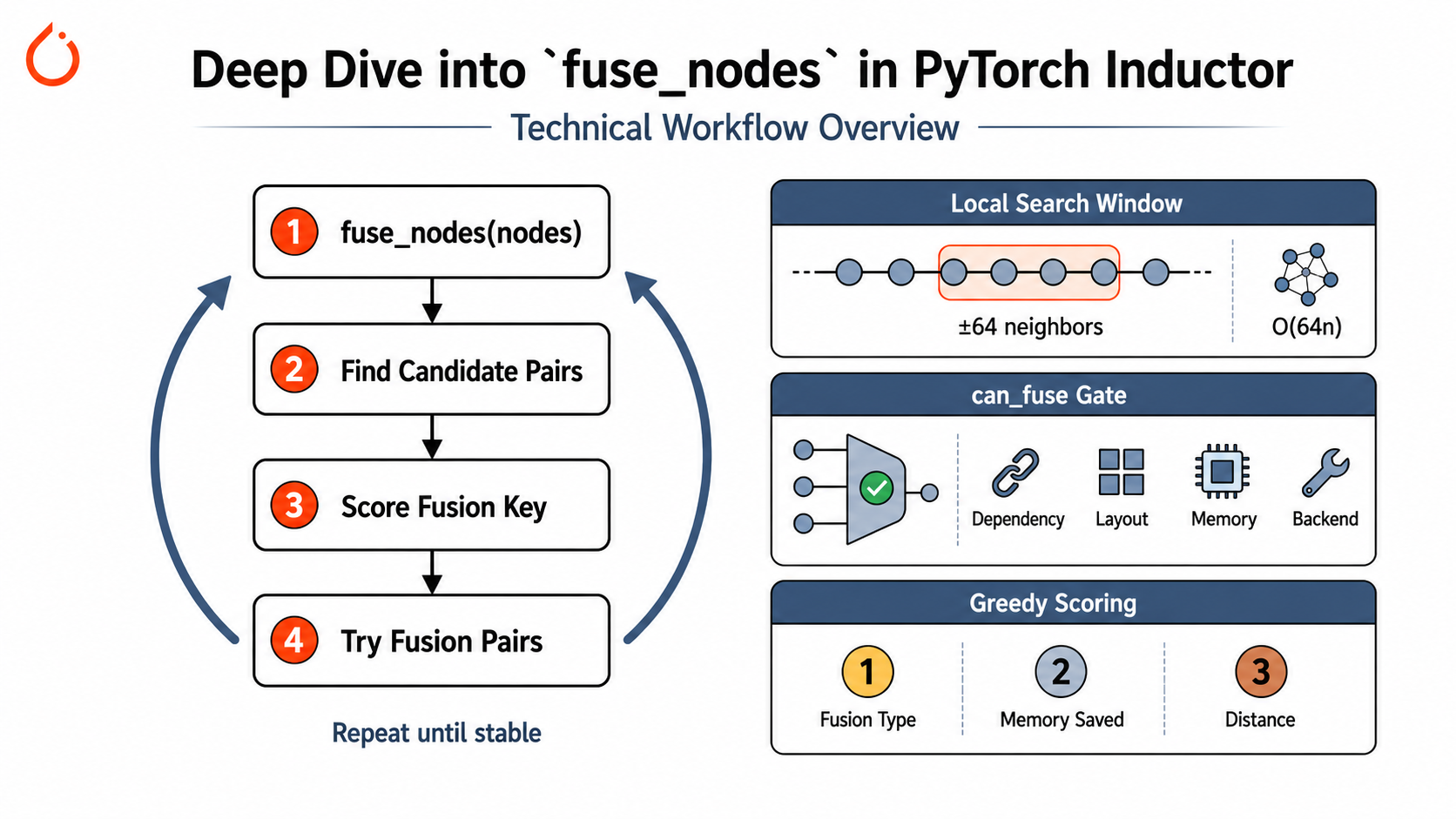
The diagram below shows the full call chain of fuse_nodes. The entire process boils down to one sentence: repeatedly find fusable node pairs in the graph, score and rank them by priority, then greedily attempt the actual fusions until the graph stops shrinking.
fuse_nodes(nodes)
│
└─► fuse_nodes_once() ×up to 10 rounds; early exit if size unchanged or =1
│
├─ 1. get_possible_fusions() ─────────────────── enumerate candidate pairs
│ │
│ ├─ [Loop 1] Group nodes by buffer_name
│ │ For each fusable node, bucket it by the buffers it reads/writes
│ │
│ ├─ [Loop 2] check_all_pairs() within each buffer group
│ │ │ ► Window optimization: only check ±64 neighbors → O(64n) not O(n²)
│ │ │
│ │ └─► can_fuse(n1, n2) ──────────────────── 8 categories of gate checks
│ │ │ ① Identity check ⑤ Topological dependency
│ │ │ ② Special node block ⑥ Dtype compatibility
│ │ │ ③ Template fast-path ⑦ Memory / size constraints
│ │ │ ④ Grouped node ban ⑧ Other backend limits
│ │ │
│ │ └─ If failed & node2 is template/foreach
│ │ → retry reversed: can_fuse(n2, n1)
│ │ (container nodes can "absorb" other nodes)
│ │
│ ├─ [Loop 3] aggressive_fusion mode
│ │ Re-group by node.group, then check_all_pairs() within each group
│ │
│ └─► get_possible_fusions_with_highest_priority() ── deduplicate & select
│ │
│ ├─ get_backend(device).get_fusion_pair_priority(n1, n2)
│ │ Backend interface: CPU/CUDA each decide fusion-method priority
│ │
│ └─ Same pair may arrive from different grouping paths
│ → keep only the highest-priority entry
│
├─ 2. score_fusion_key() ─────────────────────── score & sort candidates
│ │
│ └─► V.choices.score_fusion()
│ Based on three dimensions:
│ • Fusion type (template / reduction / ...)
│ • Estimated memory bandwidth saved
│ • Topological distance in the original graph (closer = better)
│
└─ 3. _try_fusion_pairs() ────────────────────── attempt fusions in rank order
Order is critical: fusing (A,B) first invalidates (B,C)
Phase 1: Finding Candidate Pairs - get_possible_fusions
The goal here is to sift through the entire graph and produce every node pair that is both possible and worthwhile to fuse.
Buffer Grouping - The Prerequisite for Fusion
The code first iterates over all fusable nodes and buckets each one by the buffer_name values it reads or writes, building a grouping dictionary. The intuition is straightforward: if two nodes share no buffers, fusing them is unlikely to yield any benefit because there is no intermediate buffer to eliminate and no memory traffic to save. So pair-checking is restricted to nodes within the same buffer group.
Window Optimization - Taming the Search Space
Within each buffer group, check_all_pairs enumerates pairwise candidates. A key optimization keeps this tractable: PyTorch only checks nodes within a window of plus or minus 64 neighbors in the node list. For a list of length n, this caps the number of candidate pairs at 64 * n rather than the naive n^2. This makes the fusion search feasible even on very large graphs.
can_fuse - Eight Categories of Gate Checks
Every candidate pair must survive the gauntlet of can_fuse(node1, node2). The checks include at least:
- Identity:
node1 == node2so the pair is skipped immediately. - Special node block: Nodes like
FusedMixOrderReductionsthat have already been fused cannot fuse again. - Template fast-path: Template nodes have a dedicated short-circuit that can approve fusion quickly.
- Grouped node ban:
GroupedSchedulerNodeinstances are already group-scheduled and barred from further fusion. - Topological dependency: The most critical check, ensuring fusion will not violate data-flow ordering.
- Dtype compatibility, memory and size constraints, backend-specific limits, and other implementation guards.
An interesting detail: if can_fuse(n1, n2) fails but n2 is a template or foreach node, the code retries in the reversed direction with can_fuse(n2, n1). The reason is that template and foreach nodes are effectively container nodes that can absorb other nodes into themselves, so the fusion direction matters.
Aggressive Mode
When config.aggressive_fusion is enabled, an additional grouping pass runs based on node.group. The scheduler considers nodes in the same group to be part of a larger logical unit, making them prime candidates for more aggressive fusion attempts.
Phase 2: Deduplication and Scoring
Deduplication - get_possible_fusions_with_highest_priority
The same pair (node1, node2) may be discovered through different grouping paths, once from a buffer group and once from a node group. Different paths may imply different fusion strategies, but we only want the best one.
The arbiter is the backend interface get_backend(device).get_fusion_pair_priority(node1, node2). This is dynamic dispatch: the code first resolves the backend for the current device, such as CPU or CUDA, and then asks that backend to evaluate the pair priority. The base class returns 0 by default, but each backend is free to override this.
Scoring - score_fusion_key
After deduplication, each remaining candidate pair is scored via V.choices.score_fusion(). The scoring dimensions are:
- Fusion type: Template fusions, reduction fusions, and other categories carry different weights.
- Estimated memory bandwidth saved: The core payoff metric, measuring how much data movement can be eliminated.
- Topological distance in the original graph: Closer pairs are preferred.
All candidates are sorted from highest to lowest score. That ordering directly determines the sequence in which fusions are attempted.
Phase 3: Attempting Fusions - _try_fusion_pairs
This is where fusions actually happen. The sorted order is paramount: candidates are tried from highest score to lowest, and once a node has been consumed by a fusion, any other candidate pair involving that node is automatically invalidated.
For example, suppose the candidate list contains (A, B) and (B, C), with (A, B) scoring higher. (A, B) will be fused first, after which (B, C) becomes infeasible because B has been absorbed into the fused node AB.
This greedy strategy, combined with the carefully designed scoring function, allows Inductor to find a high-quality fusion plan in reasonable time.
Takeaways
The design of fuse_nodes reflects several engineering trade-offs:
- Window optimization reduces search complexity from
O(n^2)toO(n)behavior in practice, keeping large graphs tractable. - Multi-path grouping with buffer groups, node groups, and aggressive mode captures fusion opportunities at different granularities.
- Backend dispatch lets CPU and CUDA define their own fusion preferences independently.
- Greedy ordering uses a simple but effective strategy to arbitrate between competing candidate pairs.
At a high level, this is a classic optimization pipeline: broad search to narrow filtering to greedy decision-making.